原创 Lance Fortnow 返朴
核心观点:
1. 至2021年,P/NP问题已经50岁了,但其解决方案仍遥不可及。尽管算法与硬件的卓越进步使我们可以解决许多NP完全问题,但在密码系统的破解方面仍进展甚微。
2. 随着我们持续地在机器学习以及以数据为中心的计算领域取得激动人心的进步,P/NP问题向我们提供了一个宝贵的视角,去了解在未来的机器学习领域什么是可能的,什么是不可能的。
3. 虽然P/NP问题一开始涉及复杂问题的计算求解,但如今我们将其视为绘制这个领域未来发展蓝图的一种方法。
(编者注:正文内参考文献序号为原文标注;原文发表于2022年。)
撰文 | Lance Fortnow(伊利诺斯理工学院计算机学院教授)
翻译 | 许钊箐
1971年5月4日,数学家、计算机科学家史蒂夫·库克(Steve Cook)在他的论文《定理证明过程的复杂性》(The Complexity of Theorem Proving Procedures)中向世人介绍了P/NP问题。如今,50多年过去了,全世界仍在尝试解决这一问题。在2009年,我在《ACM通讯》(Communications of the ACM)杂志上发表综述文章《P/NP问题的现状》,探讨过这一话题[13]。
自2009年那篇文章发表以来,P/NP问题及其相关的理论并没有显著的进展,但是计算领域无疑发生了巨变。云计算的发展促进了社交网络、智能手机、零工经济、金融科技、空间计算、在线教育等领域的进步,并且也许其中最重要的是数据科学与机器学习的崛起。在2009年,市值排名前十名的公司中仅仅只包含一家大型科技公司:微软。而截止至2020年9月,市值排名前七名的公司是:苹果(Apple)、微软(Microsoft)、亚马逊(Amazon)、谷歌(Alphabet)、阿里巴巴(Alibaba)、脸书(Facebook)、腾讯(Tencent)[38]。在此期间,美国计算机科学专业毕业生的数量增加了两倍多[8],但仍远远不能满足岗位的需求。
在本文中,我选择通过P/NP问题的视角来看待计算、优化以及机器学习领域的进展,而不仅仅是简单修改或更新2009年文章的内容。我们将关注这些进展是如何使我们更接近P=NP的世界,P/NP问题至今仍存在的局限性,以及已经涌现的新的研究机会。特别地,我会探讨我们是如何走向一个我称之为“Optiland”的世界,在那里我们几乎可以奇迹般地获得P=NP的许多优点,并且同时避免一些缺点,比如打破密码学的相关理论。
作为一个开放的数学难题,P/NP问题至今是其中最重要的之一;它被列入克莱数学研究所的千禧年大奖难题之一[21](该组织为其中每一个问题的求解提供100万美元的奖金)。在本文的最后,我也将陈述一些前沿计算机科学的相关理论结果。虽然这些结果没有让我们更接近于解决P/NP问题,但它们向我们展示了对于P/NP问题的思索仍然推动了该领域众多的重要研究。
P/NP 问题
是否存在300个Facebook用户彼此之间都是好友的关系?你将如何为这个问题提供一个解答?假设你在Facebook公司工作,可以访问公司所有数据,了解哪些用户是好友关系。你现在需要设计一个算法来寻找彼此都是好友并且人数足够多的朋友群体(Clique)。你可以先尝试搜索所有满足条件的300人朋友群体,但由于实际人数过多,无法全部搜索。你也可以选择一些更明智的方法,比如先尝试搜索一些小型朋友群体,之后再小的群体合并为更大的群体,但你会发现你所做的似乎都不起作用。事实上,没有人知道比遍历所有朋友群体明显更快的搜索方法,同时我们也不知道更快的方法是否不存在。
这基本上就是P/NP问题。NP代表我们可以高效检验其解答的问题。如果我告知你有300人可能形成了一个满足条件的团体,你可以相对较快地检验他们彼此之间形成的44850对用户是否都是好友关系。上文的分团问题(Clique problem)便是一个NP问题。而P则表示我们可以高效地找到解的问题。对于分团问题,我们不知道它是否在P问题这个集合中。或许会令你惊讶的是,分团问题有一个被称为NP完备(NP-complete)的性质——即当且仅当P=NP时,我们才可以高效地解决分团问题。许多其他问题也有这一性质,比如三着色问题(一副地图能否可以仅被三种颜色着色使得任意相邻的两个国家拥有不同的颜色?),旅行商问题(在众多的城市中找到一个最短路线,使得商人访问每座城市一次并回到初始的位置),以及其他成千上万的问题。
严格地来说,P表示“多项式时间”(polynomial time),对应一类求解时间是以输入长度为自变量的固定多项式的问题。而NP表示“非确定性多项式时间”(nondeterministic polynomial time),对应一类非确定性图灵机可以不可思议地选择出最佳答案的问题。在本文中,读者可以把P和NP简单地看作可高效求解的问题以及可高效验证的问题。
如果读者希望对于P/NP问题的重要性有更深入的非专业讨论,可以阅读我2009年的综述文章[13]或者我在2013年基于这篇综述文章写作的科普书籍[14]。对于更专业的介绍,由迈克尔·加里(Michael Garey)和大卫·约翰逊(David Johnson)[16]在1979年创作的专著对于需要理解哪些问题是NP完备问题的读者非常合适。这本专著至今仍然是这方面的宝贵参考资料。
为什么我们现在谈论P/NP问题?
1971年一个周二的下午,在美国俄亥俄州谢克海茨市的斯托弗萨默塞特酒店,史蒂芬·库克(Stephen Cook)在ACM计算理论专题研讨会上向与会者展示了他的论文,他证明了布尔表达式可满足性问题(Boolean Satisfiability Problem)是NP完备的,并且证明了重言式问题(Tautology)是NP困难(NP-hard)的[10]。这些定理也表明,重言式问题是一个不在P集合中不错的候选,并且我认为花费相当大的精力来尝试证明这个猜想是值得的。这样的证明将会是复杂性理论的重大突破。
与一个数学概念“约会”几乎总是一个挑战,历史上也许还有很多P/NP问题可能的诞生时间。算法和证明的基本概念可以被追溯到古希腊时期,但据我们所知,P/NP这样一般性的问题他们从未考虑过。高效计算与非确定性的理论基础是在20世纪60年代发展起来的,而P/NP问题在此之前就形成了,只是我们不知道具体时间而已。
在1956年库尔特·哥德尔(Kurt Gödel)写给约翰·冯·诺伊曼(John von Neumann)的一封信中,哥德尔本质性地描述了P/NP问题。目前我们尚不清楚,当时身受癌症侵袭的冯·诺伊曼是否阅读了这封信。直到1988年,这封信才被人们发现,并广为传播。而P/NP问题是直到理查德·卡尔普(Richard Karp)1972年发表论文[23]指出大量著名组合问题(包括分团问题、三着色问题、以及旅行商问题)是NP完备的之后才真正成为一种现象。1973年,当时在苏联的列昂尼德·莱文(Leonid Levin)在其1971年独立研究的基础上发表了一篇论文,其中定义了P/NP问题[27]。而当莱文的论文传到西方的时候,P/NP问题已经成为计算领域最重要的问题了。
乐观之地(Optiland)
在1995年的一篇经典论文中[20],拉塞尔·因帕利亚佐(Russell Impagliazzo)描述了对于P/NP问题拥有不同程度可能性的五个世界:
1. 算法世界(Algorithmica):P=NP或者某种理论上的等价,比如NP问题的快速随机算法。
2. 启发世界(Heuristica): 在最坏的情况下NP问题很难求解,但是通常情况下求解是容易的。
3. 悲观世界(Pessiland;译者注:引申自拉丁语悲观主义pessimus):我们可以轻易地构建难以求解的NP问题,但是很难构建我们知道解答的NP问题。这是所有可能性中最坏的,因为在这个世界中,我们既不能在通常情况下解决困难的问题,也不能由这些问题的难度获得任何明显的加密优势。
4. 单向加密世界(Minicrypt):单向加密函数存在,但是我们没有公开密钥加密算法。
5. 加密狂欢世界(Cryptomania): 公开密钥加密是可能的,也就是说,双方可以通过公开的信道交换加密信息。
这些对应不同情况的不同世界特意没有被正式定义。根据我们对于P/NP问题的了解,它们表明了未知的各种可能性。人们通常认为(不是全体统一地),我们生活在可以“加密狂欢”的世界里。
因帕利亚佐从P/NP的理论中总结出:“鱼与熊掌不可兼得(You can't have it all)”。我们可以求解困难的NP问题,或者可以拥有密码学,两者必有其一,但不会共存。不过,或许我们正在前往一个现实中的“乐观之地”(Optiland;译者注:与pessiland对应,引申自Optimum)。机器学习和软件与硬件优化的进展,使我们能够对于此前长期被认为是困难或不可能的问题取得进展,比如语音识别与蛋白质折叠等问题,并且在大多数情况下我们的加密协议仍然是安全的。
在我2009年的综述文章[13] “如果P=NP会怎么样?”章节里,我当时写道,“通过使用奥卡姆剃刀原则(Occam’s razor),学习变得容易了——我们只需寻找与数据一致的最简单的方法”。近乎完美的视觉识别、语言理解、翻译,以及所有其他的学习任务都变得容易解决。我们也将更好地预测天气、地震以及其他自然现象。
如今,我们可以通过面部扫描来解锁智能手机,通过询问手机问题得到通常较为理想的回复,也可以将我们的问题翻译为另一种语言。智能手机会接收关于天气和极端气候的警报,而其预测能力比我们十几年前想象的要好得多。同时,除了小长度密钥加密会受到类似暴力破解的攻击之外,密码学理论基本没有被撼动。接下来,让我们来看一看计算、优化以及学习领域最近的进展是如何将我们领入“乐观之地”的。
困难问题的求解
2016年,比尔·库克(Bill Cook, 与前文中的史蒂夫·库克没有关系)和他的同事们决定迎接这项挑战[9]:如何使用最短的路程到访英国的每一家酒吧?他们列出了24727家酒吧的名单,并确定了最后的酒吧旅行路线——一次总长度45495239米的徒步旅行。这一距离比绕地球一圈还要长一些。
实际上,库克对该问题做了一些简化:他忽略了一些酒吧使得该问题有一个合适的规模。在一些英国媒体进行报道[7]之后,许多人抱怨名单中没有他们最爱的酒吧。因此库克团队重新整理了一份包含49687家酒吧的名单,而新的行程长度是63739687米(见下图)。与之前的路径相比,人们只需要多走40%的路程,便能到访数量是之前两倍多的酒吧。这个酒吧旅行的问题与旅行商问题(最著名的NP完备问题之一)是等价的。到访49687家酒吧所有可能路线的数量大约是“3后面跟着211761个0”。当然库克的电脑不会遍历所有路线,他们使用了各种优化技术。更令人印象深刻的是,这份路线还附带一份基于线性规划对偶性的最优性证明。
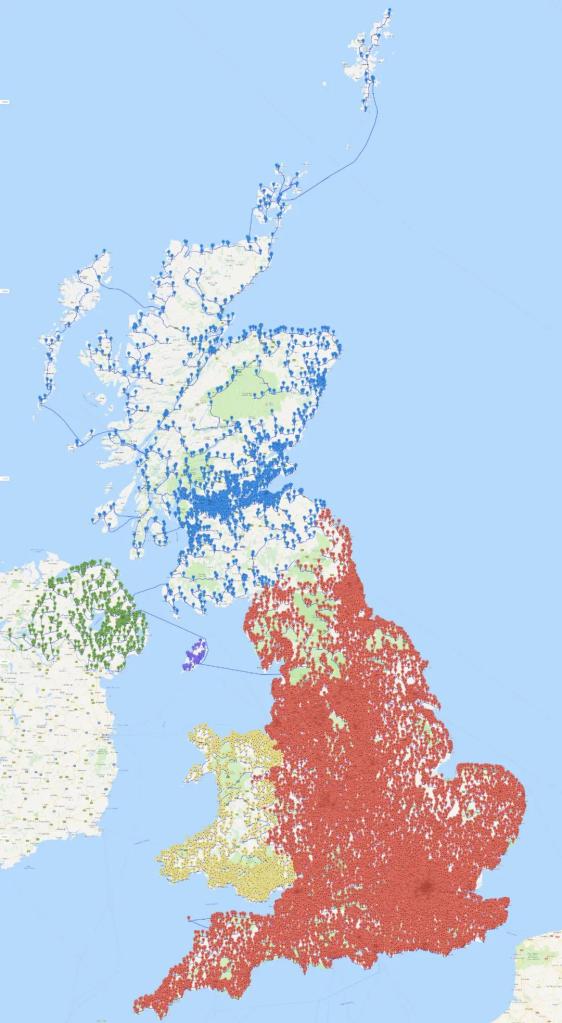
穿过49687家英国酒吧的最短路线 图片来源:math.uwaterloo.ca/tsp/uk
库克团队也承担了一个更大的任务——寻找一条穿越200多万恒星的最短路径,其中恒星之间的距离可以被计算。他们获得的路线总长度为28884456秒差距(译者注:1秒差距约为3.26光年),和理论最佳值相比只有683秒差距的差别。
除了旅行商问题,我们在求解布尔可满足性问题和混合整数规划问题(Mixed-integer programming question)领域也取得了重大进展——一种线性规划方法的变体,其中一些变量(不一定是全部)必须是整数。通过使用高度精炼的启发式方法、高速处理器、专业硬件以及分布式云计算,人们基本已经可以解决实践中出现的具有数以万计的变量和数十万甚至上百万的约束的问题。
面对需要求解的NP问题,人们通常会将问题转述为布尔可满足性问题或混合整数规划问题,进而使用最好的求解器求解。这些工具已经被成功地应用在电路与编码的验证与自动化测试、计算生物学、系统安全、产品与包装设计、金融交易中,甚至用于求解困难的数学问题。
数据科学与机器学习
如今,任何《ACM通讯杂志》的读者和其他大多数人都不会忽视机器学习带来的变革性影响,尤其是通过神经网络实现的机器学习。使用人工神经元(笼统地讲,计算加权阈值函数)实现建模计算的概念可以追溯到20世纪40年代沃伦·麦卡洛克(Warren McCulloch)和沃尔特·皮茨(Walter Pitts)[28]的研究。在20世纪90年代,约书亚·本希奥(Yoshua Bengio)、杰弗里·辛顿(Geoffrey Hinton)和杨立昆(Yann LeCun)[26]提出了反向传播等算法,为多层神经网络学习训练的发展奠定了基础。更快、更广泛的分布式计算、专业硬件和海量数据也帮助并推动了机器学习的发展,使得它可以非常出色地完成众多原本需要人类完成的任务。计算机协会(the Association for Computing Machinery,ACM)也为本希奥、辛顿和立昆授予了2018年的图灵奖,以表彰他们的工作对人类社会产生的深远影响。
那么,机器学习与P/NP问题有什么联系?(在本节中,当我们提及P=NP,它表示所有的NP问题在实践中都有相关的高效算法。)奥卡姆剃刀原则指出,“如无必要,勿增实体”,或者说,最简单的解释可能才是正确的。如果P=NP,我们可以利用这一思想来建立一个强大的学习算法:找到一个与数据一致的最小的回路。但即便可能没有P=NP这个结论,机器学习也可以近似地实现这种方法,从而赋予了神经网络惊人的能力。然而,神经网络不太可能是那个“最小的”回路。如今使用深度学习技术训练的神经网络往往结构是固定的,其参数与网络中的权重有关。为了拥有足够的表达能力,人们通常需要设置数百万甚至更多的权重参数。而数量众多的参数限制了神经网络的能力:它们可以很好地进行面部识别,但是却无法根据示例来学习如何进行乘法运算。
通用分布(Universal distribution)和GPT-3 让我们考虑任意长度二进制字符串的分布。尽管均匀分布是明显不合理的,但是我们是否可以构建分布使得任意相同长度的字符串拥有相同的概率?实际上,有些字符串确实会比其他的更重要。比如,π的前100万位数字比随机生成一个100万位数字更有意义。因此或许你会希望给更有意义的字符串设置更高的概率。实现这一目标的方法很多,而实际上存在一个接近于任何其他可计算分布的通用分布(读者可以参考科尔什赫等人的文章[25])。通用分布与学习训练有很大的联系,例如,任意以小误差率学习这种分布的算法将可以学习所有可以计算的分布。可惜的是,即便P=NP,通用分布也是不可计算的。不过,如果P=NP,我们仍然可以得到一些有用的东西——我们可以创建一个可高效计算的分布,使得它对于其他可高效计算的分布是通用的。
我们能从机器学习中获得什么?以GPT(Generative Pre-trained Transformer,生成式预训练转换器)为例,特别是2020年发布的GPT-3[5]。GPT-3从尽可能多的书面语料库中提取了4100亿个标记,进而训练了1750亿个参数。它可以回答问题,可以根据提示书写文章,甚至可以生成代码。尽管它还有漫长的优化之路要走,但是它已经可以像人类一样创造内容,并因此受到好评。我们可以把GPT-3看作是一种分布,并考虑算法输出对应的概率——即一个弱版本的通用分布。如果我们以一个给定的前缀限制通用分布,那么它就提供一个由该前缀提示的随机样本。GPT-3也可以基于这样的提示,无需进一步训练就能处理极大范围的相关领域知识。随着这方面研究的进展,我们也将越来越接近一个通用度量标准并从中实现内置式学习:基于给定上下文生成一个随机的例子。
科学与医药 在科学世界,我们已经通过大规模模拟取得了众多进展,比如探索核聚变反应。研究者们使用一种科学方法的范式:首先对于物理系统建立假设;然后使用模型进行预测;再用实验模拟检验该预测,而不是直接实现核聚变反应。如果测试结果与预期不同,再修改或推翻这个模型并重复以上的过程。
在我们拥有一个有说服力的模型之后,我们可以在现实反应堆中进行一些昂贵的实验测试。如果P=NP,像上文提及的,我们可以使用奥卡姆剃刀理论来建立假说——找到一个与数据一致的最小回路。机器学习的技巧可以紧接着沿着这个思路自动地创建假设。不管数据是来自于模拟、实验还是传感器,机器学习都可以创建出匹配数据的模型。然后我们可以使用这些模型来进行预测,并像前文提到过的那样检验做出的预测。
尽管机器学习可以帮助我们找到未发现的假设和模型,但所获得的结果未必是正确的。我们通常可以接受有95%置信水平的假设(这意味在20个不合格的假设中,有一个可能会被接受)。机器学习与数据科学的工具为我们生成假设的同时,也带来了结果不符合事实的风险。医学研究人员,特别是试图解决癌症等疾病的研究人员,常常遇到算法上的阻碍,因为生物系统极其复杂。我们知道DNA构成一种编码,它描述了我们的身体如何形成以及身体不同部分的功能,但我们对其运作原理知之甚少。
2020年11月30日,谷歌的DeepMind公司发布了AlphaFold——一种基于氨基酸序列预测蛋白质结构的新算法[22]。AlphaFold的预测准确度几乎达到了人工实验的水平,即通过实验构建氨基酸序列并测试其生成的蛋白质结构。虽然关于DeepMind是否真的“解决”了蛋白质折叠的问题仍存争议,并且现在便评估其影响力还为时过早,但从长远来看,它为我们提供了一个新的数字化工具来研究蛋白质,理解它们是如何相互作用,并学习如何设计蛋白质来对抗疾病。
P/NP之外:象棋与围棋 NP问题就像解谜游戏。数独问题就是NP完备的:在一个任意大小的宫格上,给定一些初始数字,然后求解其余空格中数字。但是对于两位玩家轮流执子的回合制游戏,比如象棋和围棋,如果我们想知道谁会在给定棋局下获胜,情况又会怎么样呢?事实上,即便是P=NP,我们也未必可以找到完美的棋类算法。我们不得不考虑对于黑子的每一步,白子都可以走出合适的一步,并不断循环直到白棋胜利。而设计这种交替的算法仅仅依靠P=NP是不够的。这一类游戏的算法设计被称为PSPACE-hard——在没有时间限制下,使用合理的存储容量进行计算是困难的。根据具体的规则设定,象棋和围棋的算法设计会更有难度。(感兴趣的读者可以阅读德迈纳与赫恩的文章[11]。)
不过,这并不意味着在假设P=NP的前提下,我们不能找到一个好的棋类算法。你可能做出一个大小合适的高效计算机程序,使其优于所有比它体量略小的高效程序。另一方面,即便没有P=NP这一假设,计算机在棋类方面已经足够强大。在1997年,IBM的超级电脑“深蓝”击败了当时的国际象棋世界冠军加里·卡斯帕罗夫(Gary Kasparov),然而在当时,即便是与有实力的业余选手的对决,围棋程序也难以取胜。在这之后,机器学习在计算机游戏的算法设计方面取得了巨大的进步。让我们直接跳过这段悠久的历史,来看看2017年DeepMind开发的AlphaZero[35]。
AlphaZero使用了一种被称为蒙特卡洛树搜索(MCTS)的技术——让双方玩家随机地落子从而决定最佳的棋路方案。AlphaZero使用深度学习来预测棋局的最佳分布,以优化使用MCTS获胜的机会。虽然AlphaZero并不是第一个使用MCTS的程序,但是它没有任何内置策略或者访问之前的棋类数据库——它仅仅假设了游戏的规则。这也使得AlphaZero在国际象棋和围棋上都表现得出色,这两种游戏除了交替回合制和固定大小的棋盘之外截然不同。DeepMind最近进一步地研究了MuZero[33]——它甚至没有完整的规则,仅仅有一些棋盘位置的表示,一系列符合规则的落子,以及哪些情况是赢、输或者平局。现在我们已经明白,在国际象棋和围棋中,纯粹的机器学习可以很轻易地击败人类或者其他算法。而人为地干预只会妨碍它。对于象棋和围棋这类游戏,即便P=NP不足以解决这类问题,但机器学习却可以取得成功。
可解释的人工智能 很多机器学习算法似乎已经都运行得很好,但是我们却不理解为什么。如果你去观察为了语音识别而训练的神经网络,你通常会难以理解它为何做出这样的选择。我们为什么要关心这个问题呢?以下是一些原因:
1. 置信:我们如何知道神经网络运行正确?除了检查输入和输出,我们不会做其他任何的分析。不同的应用场景会有不同的置信水平:Netflix推荐了一部水平不高的电影没什么关系,但如果是自动驾驶的汽车选择了一个错误的转弯,结果就很严重。
2. 公平:有很多例子表明,通过数据训练的算法受到了数据中有意或无意的偏差的影响。如果我们不理解程序,我们如何发现这些数据中的偏差?
3. 安全:如果使用机器学习来监管安全系统,我们将不知道哪些漏洞仍然存在,特别是当我们的敌手是不断变化的时候。但如果我们理解代码,我们就可以发现并修补安全漏洞。当然,如果敌手获得了代码,他们也可以发现漏洞。
4. 因果关系:目前我们最多只能检查机器学习算法是否与我们想要的输出类型相关。理解代码可以帮助我们理解数据中的因果关系,从而在科学与医学方面取得新的进步。
如果P=NP,我们会得到一个更好的情况吗?如果我们有一个NP完全问题的快速算法,你可以将其用于匹配问题或旅行商问题,找到可能的最小回路,但你不会知道为什么这个回路是对的。另一方面,我们想要一个可解释算法的原因是我们希望可以理解它的性质,但如果P=NP,我们可以直接导出这些性质。现在研究可解释的人工智能会议涌现出来,例如ACM FAccT会议。
机器学习的局限性 虽然在过去十年中,机器学习已经展现了许多令人惊奇的结果,但很多系统还远未达到完美的水平,在大多数应用场景中,人类仍然更胜一筹。人们也将继续通过新的优化算法、数据收集与专业硬件来提高机器学习的能力。不过,机器学习似乎确实有其局限性。正如我们上文提到过的,机器学习让我们一定程度的接近P=NP,但却永远无法替代P=NP——机器学习在密码破解方面进展甚微,我们也将在本文后面看到这一点。
机器学习似乎无法学习简单的算术——例如对大量的数字求和或者大数之间相乘。人们可以想到将机器学习与符号运算的数学工具结合起来。然而,尽管在定理证明方面我们取得了一些令人瞩目的进展[19],但这与我们期待中的实际科研任务仍距离遥远,即选取一篇科研文章,文中证明还未正式完成,使用AI系统补充细节并检验证明。
而P=NP将使这些任务变得简单,或者至少易于处理。机器学习在面对不属于其训练分布的任务时可能表现不佳。但这可能是概率较低的极端情况,例如训练数据中并未获得很好代表某个种族的人脸识别;或者可能是一种对抗性的尝试——通过对输入进行微小的更改来强行获得不同的输出,比如把停车标志修改几个像素,从而让算法将其识别为一个限速标志[12]。深度神经网络算法可能有数百万个参数,因此它们在分布之外的泛化效果可能不理想。如果P=NP,我们可以获得最小尺寸的模型从而有望实现更好的泛化,但如果没有相应的实验,我们永远也无法验证。
尽管机器学习令人印象深刻,但我们还没有获得任何接近于通用人工智能的东西——这个术语指的是对于一个主题有真正的理解,或是实现真正的意识或自我认知的人工系统。定义这些术语可能是棘手的、有争议的,甚至是不可能的。于我个人而言,我从未见到过一个关于意识的正式定义,能够体现我对于意识的直观认识。我怀疑即使P=NP,我们也永远无法实现强意义下的通用人工智能。
密码学
虽然我们在解决NP问题方面取得了很大进展,但是密码学的多种理论,包括单向函数(one-way functions)、安全散列算法(secure hashes)以及公钥密码学似乎都完好无损。如果NP问题存在一个高效的算法,那么除了那些在信息学上安全的密码系统,比如一次性密码簿和一些基于量子物理学的密码系统,其他所有密码系统都会被破解。我们已经见证了很多成功的网络安全攻击,但它们通常源于糟糕的代码漏洞、很弱的随机数生成器或者人为疏漏,很少是因为密码学理论的问题。
现在大多数CPU芯片都内置了AES(Advanced Encryption Standard),因此一旦我们使用了公钥加密系统设置私钥,我们就可以像发送普通文本一样轻松地发送加密后的数据。加密技术为区块链和加密货币的发展提供了动力,这意味着人们对于加密技术的信任足以让他们愿意把货币换成比特。迈克尔·卡恩斯(Michael Kearns)和莱斯利·瓦利安特(Leslie Valiant)在1994年证明[24],如果可以学习到最小的回路,甚至只是学到了最小的有界层的神经网络,那么它们就可以被用来分解质因数并破解公钥加密系统。而到目前为止,机器学习算法还从未成功破解过加密协议,不过也没有人期望机器学习算法可以成功。
为什么我们在许多其他NP问题取得了进展,而加密系统仍可以表现良好?在密码学中,我们可以选择问题,特别是可以将其设计成难以计算并可被广为测试的。而其他的NP问题通常来自应用问题或自然界。它们往往不是最困难的,也更容易折服于当下技术。
量子计算似乎威胁着当下保护我们互联网交易的公钥加密协议。秀尔算法(Shor’s algorithm)[34]可以进行质因数分解与其他数论计算。这种忧虑可以通过几种方式来缓和。尽管量子计算取得了一些令人印象深刻的进展,但要开发出能处理足够多纠缠比特的量子计算机,从而在一定规模上实现秀尔算法,我们可能仍需要几十年甚至几个世纪的时间。此外,研究者们也在开发可抵抗量子攻击的公钥密码系统并取得了一定的进展。更多量子计算内容我们将在后文详细讨论。
我们不知道因式分解问题是否是NP完备的,所以即便我们没有大规模的量子计算机,数学上的突破也有可能会带来高效的算法。但无论你对量子领域的未来有什么样的看法,如果拥有多种方法来优化公钥加密系统,它们可能都会派上用场。
如摩擦力般的复杂性
我们可以从计算复杂性中获得什么?此时,密码学可能会从你的脑海浮现。但或许就像存在摩擦力一样,宇宙使得某些计算很困难是有原因的。在物理世界中,克服摩擦力通常以消耗能量为代价,但是如果没有摩擦力,我们寸步难行。在计算世界中,错综复杂的计算一般会使计算过程缓慢而低效,但如果没有复杂性,就像没有摩擦力一样,我们也会有很多其他的问题。而P=NP在很多情况下,会让我们消除“摩擦力”。
计算领域的最新进展表明,消除“摩擦力”有时会产生负面影响。例如人们不能直接阅读别人思想,只能看到其采取的行动。经济学家有一个术语,“偏好揭示”(preference revelation),旨在根据人们的行为来确定其偏好。在过去,由于缺乏数据与足够的算力,这一领域一直被认为最多只是非常不精确的一种艺术。
而如今,我们已经收集到了相当可观的数据——来自人们的网络搜索、相片与视频、网购记录、虚拟与现实世界中的访问记录、社交媒体上的活动等等。而且,机器学习可以处理这些庞杂的信息,并对人们的行为做出异常精确的预测。如今,计算机比我们更了解我们自己。
我们甚至已经有足够的技术制作一副眼镜,戴上它就可以让我们了解对面人的名字、兴趣与爱好,甚至其政治立场。因此这种信息上的复杂性已不再赋予我们隐私。人们需要依赖法律和企业责任来保护隐私。
计算上的“摩擦力”不仅体现在隐私这一方面。在1978年,美国政府解除了对航空公司的定价管制,但如果想要找到一条航线的最佳价格,人们往往需要给多家航空公司打电话咨询,或者通过旅行社代理购票,当然旅行社也并不总是有动力去寻找最低的价格。因此航空公司致力于打造声誉,一些公司侧重优质的服务,另一些公司可以提供更低的价格。今天,我们可以很容易地找到最便宜的航班,因此航空公司在价格这个单一维度上投入了相当大的努力,他们通过计算优化定价并以牺牲飞行体验的代价来安排座位。
这种“摩擦力”在以前也有助于打击学生的作弊行为。在上世纪80年代,我读大学时必须计算作答的微积分问题,现在已经可以被Mathematica软件轻松解决。在我的入门理论课程中,我在为学生准备作业与考题的时候遇到了麻烦——答案都可以在网上找到。随着GPT-3和其后续版本能力日益强大,甚至连论文与代码都可以自动生成,如果GPT这类的工具已经可以解决对于学生来说最复杂的问题,我们要如何激发学生?
股票交易过去是在现场进行的,交易员用手势来进行价格匹配。如今,交易算法自动地调整以适应新的价格,偶尔会导致价格瞬间暴跌。机器学习技术的发展已经引领了决策系统、人脸识别,将社交媒体内容与用户,还有司法判决进行大规模匹配。这些决策系统带来了一些好的改变,但也为我们带来了重大的挑战,比如放大偏见、加剧政治上的两极分化[30]。本文不详细探讨这个话题。
以上提到的这些只是许多可能的场景中的一小部分。作为计算机科学家,我们的目标是使计算尽可能的高效和简单,但我们也必须牢记减少“摩擦力”的代价。
量子计算机的能力
随着摩尔定律的极限越来越明显,计算机科学家们已经将目光投向非传统的计算模型以追寻下一阶段的突破。这促进了量子计算理论与应用的发展。大型科技公司,如谷歌、微软和IBM,还有一大批初创公司,都已在量子计算机开发上投入了大量资源。美国已经启动了国家量子计划(National Quantum Initiative),其他国家,尤其是中国,也都加入了这一行列。
2019年,谷歌[1]宣布其使用了一台拥有53个量子比特的量子计算机实现了“量子遥遥领先”,解决了当前传统计算无法解决的计算任务。尽管有些人质疑这一说法,但我们确实正处在量子计算新时代的边缘。然而我们还远没有达到实现皮特·秀尔(Peter Shor)算法[34]所需要的数万个量子比特的水平,从而解决当今计算机计算质因数分解问题。通常来说,量子计算被描述为由比特表示的状态数,比如53量子比特的机器有253个状态。这似乎表明,我们可以使用量子计算通过创建足够多的状态来解决NP完全问题——例如,在一个图结构中,检验所有可能满足条件的团体。可惜的是,量子算法操控这些状态是受限的,而且所有的证据都表明,除了由格罗弗(Grover)算法[18]给出的二次加速改善,量子计算机无法解决NP完备问题[3]。
复杂性的进展
自2009年我发表那篇综述文章之后,我们在理解高效计算能力方面取得了几项重大进步。虽然这些结果对于解决P/NP问题没有带来显著的进展,但依旧展现了它们是如何继续启发后续优秀研究的。
图同构:一些NP问题可能既不是P(高效可解),也不是NP完备的(像分团问题一样难)。其中我们前文提及的最著名的质因数分解问题,仍然需要指数级的时间来求解。而对于另一个类似的问题——图同构问题,我们最近见证了激动人心的进展。图同构指的是在重新标号的意义下,两个图是否相同。以Facebook为例,给定两个千人的群组,我们能否将名字在两个群组中以一种方式相互对应,并保持人们之间的好友关系?
20世纪80年代发表的与交互性证明相关的结果为证明图同构不是NP完备的提供了强有力的证据[4]。而且即便是简单的启发式算法通常也可以快速解决这类问题。可是我们仍然缺乏一个适用于所有情况的多项式时间的图同构算法。对于该问题,拉斯洛·巴拜(László Babai)在2016年取得了突破性成果[2],他提出了一种图同构的拟多项式时间的算法。P对应的问题的算法所用的是多项式时间,时间是nk,其中k是常数,n是输入数据的大小,如每一个群体的人数。而拟多项式时间的算法的运行时间是nklog n,与多项式时间相比要差一些,但与我们预料中NP完备问题求解所需的指数时间
相比已经有了巨大的进步。
巴拜的证明是一份将组合学与群论结合的杰出工作。尽管让算法在多项式时间内运行结束仍需要很多新的突破,但巴拜给出了一个重要的理论结果,是P与NP完备之间最重要问题之一的重大进展。
电路设计:如果在完备的基(与门、或门、非门)下,小型电路不能求解NP问题,则P≠NP。虽然上世纪80年代有很多关于电路复杂度的研究成果问世,但它们都没能接近于证明P≠NP。2009年的综述文章指出,在此前的20年里,电路复杂性领域没有取得新的重大成果。这种情况一直持续到2010年。1987年,拉兹波洛夫(Razborov)[32]和斯莫伦斯基(Smolensky)[36]证明了对于固定素数p对应的常数深度电路——由取余电路(Modp)、与门、或门、非门电路组成——是不可能计算大多数函数的。不过,如果是有6对应的取余电路(Mod6),存在少量的一些证明工作。但即使是证明NEXP(一种NP的指数时间版本)不能被常数深度的、由与或非门电路以及6对应的取余电路组成的小型电路计算这一问题,其仍在几十年中未被解决。因此常数深度的电路被认为在计算上能力很弱。在这方面工作的缺乏也反映了我们在阐释计算模型局限性这一领域取得的进展十分有限。
在2010年,瑞恩·威廉姆斯(Ryan Williams)[39]证明了NEXP确实不能被常数深度、由6对应的取余电路或任意其他取余电路的小型电路计算求解。他构造了一种新技术,应用了可满足性算法。这种算法比尝试所有赋值并使用几种复杂工具来获得下界要好一些。后来,威廉姆斯和他的学生科迪·默里(Cody Murray)[29]在此结果上更进一步,证明了即便是不确定的拟多项式时间的算法,也不存在对应的常数深度的、带有固定m对应的取余电路(Modm)的小型电路。然而证明不存在任意深度的小型电路可以求解NP问题(这正是证明P≠NP所需要的)仍然遥不可及。
复杂性的反击:在2009年的综述文章中,有一节题为“新希望”[13]。在这一节中,我们基于克坦·穆穆利(Ketan Mulmuley)和米林德·索霍尼(Milind Sohoni)提出的代数几何与表示理论,讨论了一种新的几何复杂性理论来攻破P/NP问题。简而言之,穆穆利和索霍尼试图构造高维多边形,以体现代数形式的NP问题的性质,并表明它具有任意与P问题的代数性质相对应多边形不同的性质。他们的猜想之一是认为多边形包含某种表示论的结构。然而在2016年,彼得·布尔吉瑟(Peter Bürgisser),克里斯蒂安·艾肯迈尔(Christian Ikenmeyer),和格蕾塔·帕诺娃(Greta Panova)[6]证明这种方法不会成功。
尽管布尔吉瑟、艾肯迈尔、与帕诺娃的工作否定了几何复杂性理论(GCT)区分P与NP问题的可能,人们仍然有可能根据表示论结构的数量构造不同的多边形。只不过我们不再应该期待GCT理论可以在不久的将来解决P/NP问题。
不可能的可能性
当我们思考P/NP问题时,我们发现它有许多不同的含义。P/NP是正式定义的、长时间悬而未决、仍有百万美元悬赏的一个数学问题。在本文中,我们看到通过可计算性理论、电路设计、证明和代数几何等工具试图解决P/NP问题的努力。目前我们还没有一种强有力的方法解决P/NP问题。甚至从某种意义上说,我们到解决这个问题的距离比以前任何时候都要远。
还有一些NP问题是我们希望或需要解决的。在1976年的经典文献《计算机与难解性:一本NP完备性理论的指南》中[16],加里(Garey)与约翰逊(Johnson)举了一个例子:一位倒霉的员工被要求解决一个NP完备的优化问题。最后这位员工找到老板说:“我找不到一个高效的算法,但这世界上的天才名流也一样找不到。“言外之意是老板不应该解雇这位员工,因为雇佣其他人也无法解决这个问题。
在P/NP问题的研究早期,我们将NP完备性看作一种障碍——这些问题是我们无法解决的。但随着计算机与算法的发展,人们发现通过启发式算法、近似算法和暴力计算的结合,我们也可以在NP问题上取得进展。在加里和约翰逊的故事中,如果我是老板,我不会解雇这位员工,而是建议尝试使用混合整数规划、机器学习或者暴力搜索等方法。NP完备意味着不可能的时代已经过去了。现在NP完备仅仅意味着可能没有一种算法可以永远有效和可扩展。
在我2013年关于P/NP问题的书中[14],有一章名为“美丽的世界”。在这一章中,我想象了一个理想化的世界:一位捷克数学家在这个世界中证明了P=NP,从而得出一个对于所有的NP问题都非常高效的算法。尽管我们现在没有,也很可能永远不会生活在这样理想的世界,但是随着我们在计算上一步一步地前进,我们已经实现了很多医学进步,打造出与现实难以区分的虚拟世界,发明出创造新艺术作品的机器学习算法,P=NP所带来的美妙或没那么美妙的结果似乎不再遥不可及。
我们正走在几乎完全颠覆P/NP问题的意义的道路上。与其将其认为是一种障碍,不如将P/NP问题看作一扇为我们指引方向,展现不可能中的可能性的大门。
致谢
感谢乔希·格罗乔(Josh Grochow)与我对GCT问题非常有帮助的讨论,以及库克允许我们使用相关图片。同样感谢乔希以及审稿人对于本文的建议与帮助。本文的一些材料改编自作者的博客。
参考文献
[1] Arute, F., Arya, K., Babbus, R., Bacon, D., Bardin, J.C., Barends, R., Biswas, R., Boxio, S., Brandao, F.G.S.L., Buell, D.A., et al. Quantum supremacy using a programmable superconducting processor. Nature 574, 7779 (2019), 505–510. https://doi.org/10.1038/s41586-019-1666-5
[2] Babai, L. Graph isomorphism in quasipolynomial time [extended abstract]. In Proceedings of the 48th Annual ACM Symposium on Theory of Computing (2016), 684–697. https://doi.org/10.1145/2897518.2897542
[3] Bennett, C., Bernstein, E., Brassard, G., and Vazirani, U. Strengths and weaknesses of quantum computing. SIAM J. Comput. 26, 5 (1997), 1510–1523.
[4] Boppana, R., Håstad, J., and Zachos, S. Does co-NP have short interactive proofs? Information Processing Letters 25, 2 (1987), 127–132.
[5] Brown, T.B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D.M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Suskever, I., and Amodei, D. Language models are few-shot learners (2020). arXiv:2005.14165 [cs.CL]
[6] Bürgisser, P., Ikenmeyer, C., and Panova, G. No occurrence obstructions in geometric complexity theory. J. of the American Mathematical Society 32, 1 (2019), 163–193. https://doi.org/10.1090/jams/908
[7] Coldwell, W. World's longest pub crawl: Maths team plots route between 25,000 UK boozers. The Guardian (Oct. 21, 2016). https://www.theguardian.com/travel/2016/oct/21/worlds-longest-pub-crawlmaths-team-plots-route-between-every-pub-in-uk
[8] CRA Taulbee Survey. Computing Research Association (2020), https://cra.org/resources/taulbee-survey.
[9] Cook, B. Traveling salesman problem (2020),
[10] Cook, S. The complexity of theorem-proving procedures. In Proceedings of the 3rd ACM Symposium on the Theory of Computing (1971), 151–158.
[11] Demaine, E.D. and Hearn, R.A. Playing games with algorithms: Algorithmic combinatorial game theory. Games of No Chance 3: Mathematical Sciences Research Institute Publications, Vol. 56. Michael H. Albert and Richard J. Nowakowski (Eds.), Cambridge University Press (2009), 3–56.
[12] Eykholt, K., Evtimov, I., Fernandes, E., Li, B., Rahmati, A., Xiao, C., Prakash, A., Kohno, T., and Song, D. Robust physical-world attacks on deep learning visual classification. In Proceedings of the IEEE Conf. on Computer Vision and Pattern Recognition (2018).
[13] Fortnow, L. The status of the P versus NP problem. Commun. ACM 52, 9 (Sept. 2009), 78–86. https://doi.org/10.1145/1562164.1562186
[14] Fortnow, L. The Golden Ticket: P, NP and the Search for the Impossible. Princeton University Press, Princeton, (2013). https://goldenticket.fortnow.com
[15] Fortnow, L and Gasarch, W. Computational Complexity. https://blog.computationalcomplexity.org
[16] Garey, M. and Johnson, D. Computers and Intractability. A Guide to the Theory of NP-Completeness. W.H. Freeman and Company, New York, (1979).
[17] Gödel, K. Letter to John von Neumann. (1956). https://www2.karlin.mff.cuni.cz/~krajicek/goedel-letter.pdf
[18] Grover, L. A fast quantum mechanical algorithm for database search. In Proceedings of the 28th ACM Symposium on the Theory of Computing (1996), 212–219.
[19] Hartnett, K. Building the mathematical library of the future. Quanta Magazine (Oct. 1, 2020). https://www.quantamagazine.org/building-the-mathematical-library-of-the-future-20201001/.
[20] Impagliazzo, R. A personal view of average-case complexity theory. In Proceedings of the 10th Annual Conference on Structure in Complexity Theory. IEEE Computer Society Press (1995), 134–147. https://doi.org/10.1109/SCT.1995.514853
[21] Jaffe, A. The Millennium Grand Challenge in Mathematics. Notices of the AMS 53, 6 (June/July 2006), 652–660.
[22] Jumper, J., Evans, R., Pritzel, A., Green, T., Figurnov, M., Tunyasuvunakool, K., Ronneberger, O., Bates, R., Žídek, A., Bridgland, A., Meyer, C., Kohl, S.A.A., Potapenko, A., Ballard, A.J., Cowie, A., Romera-Paredes B., Nikolov, S., Jain, R., Adler, J., Back, T., Petersen, S., Reiman, D., Steinegger, M., Pacholska, M., Silver, D., Vinyals, O., Senior, A.W., Kavukcuoglu, K., Kohli, P., and Hassabis, D. High accuracy protein structure prediction using deep learning. In 14th Critical Assessment of Techniques for Protein Structure Prediction (Abstract Book) (2020), 22–24. https://predictioncenter.org/casp14/doc/CASP14_Abstracts.pdf
[23] Karp, R. Reducibility among combinatorial problems. In Complexity of Computer Computations, R. Miller and J. Thatcher (Eds.). Plenum Press, New York, (1972), 85–103.
[24] Kearns, M. and Valiant, L. Cryptographic limitations on learning boolean formulae and finite automata. Journal of the ACM 41, 1 (Jan. 1994), 67–95. https://doi.org/10.1145/174644.174647
[25] Kirchherr, W., Li, M., and Vitányi, P. The miraculous universal distribution. The Mathematical Intelligencer 19, 4 (Sep. 1, 1997), 7–15. https://doi.org/10.1007/BF03024407
[26] LeCun, Y., Bengio, Y., and Hinton, G. Deep learning. Nature 521, 7553 (May 1, 2015), 436–444. https://doi.org/10.1038/nature14539
[27] Levin, L. Universal'ny̆ie pereborny̆ie zadachi (Universal search problems: in Russian). Problemy Peredachi Informatsii 9, 3 (1973), 265–266. Corrected English translation in.37
[28] McCulloch, W.S. and Pitts, W. A logical calculus of the ideas immanent in nervous activity. The Bulletin of Mathematical Biophysics 5, 4 (Dec. 1, 1943), 115–133. https://doi.org/10.1007/BF02478259
[29] Murray, C. and Williams, R. Circuit lower bounds for nondeterministic quasi polytime: An easy witness Lemma for NP and NQP. In Proceedings of the 50th Annual ACM SIGACT Symposium on Theory of Computing (2018), 890–901. https://doi.org/10.1145/3188745.3188910
[30] O'Neil, C. Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy. Crown (2016), New York.
[31] Peikert, C. Lattice cryptography for the Internet. In Post-Quantum Cryptography, Michele Mosca (Ed.). Springer International Publishing, Cham (2014), 197–219.
[32] Razborov, A. Lower bounds on the size of bounded depth circuits over a complete basis with logical addition. Mathematical Notes of the Academy of Sciences of the USSR 41, 4 (1987), 333–338.
[33] Schrittwieser, J., Antonoglou, I., Hubert, T., Simonyan, K., Laurent Sifre, L., Schmitt, S., Guez, A., Lockhart, E., Hassabis, D., Graepel, T., Lillicrap, T., and Silver, D. Mastering Atari, go, chess and shogi by planning with a learned model. Nature 588, 7839 (Dec. 1, 2020), 604–609. https://doi.org/10.1038/s41586-020-03051-4.
[34] Shor, P. Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer. SIAM J. Comput. 26, 5 (1997), 1484–1509.
[35] Silver, D., Hubert, T., Schrittwieser, J., Antonoglou, I., Lai, M., Guez, A., Lanctot, M., Sifre, L., Kumaran, D., Graepel, T., Lillicrap, T., Simonyan, K., and Hassabis, D. A general reinforcement learning algorithm that masters chess, shogi, and go through self-play. Science 362, 6419 (2018), 1140–1144. https://doi.org/10.1126/science.aar6404
[36] Smolensky, R. Algebraic methods in the theory of lower bounds for Boolean circuit complexity. In Proceedings of the 19th ACM Symposium on the Theory of Computing (1987), 77–82.
[37] Trakhtenbrot, R. A survey of Russian approaches to Perebor (brute-force search) algorithms. Annals of the History of Computing 6, 4 (1984), 384–400.
[38]Wikipedia contributors. List of public corporations by market capitalization. Wikipedia, the Free Encyclopedia. https://en.wikipedia.org/w/index.php?title=List_of_public_corporations_by_market_capitalization&oldid=1045945999.
[39] Williams, R. Nonuniform ACC circuit lower bounds. Journal of the ACM 61, 1, Article 2 (Jan. 2014). https://doi.org/10.1145/2559903.
本文经作者授权发表于《返朴》,原文译自Fortnow, Lance. "Fifty years of P vs. NP and the possibility of the impossible." Communications of the ACM 65.1 (2021): 76-85. DOI: 10.1145/3460351

版权说明:欢迎个人转发,任何形式的媒体或机构未经授权,不得转载和摘编。转载授权请在「返朴」微信公众号内联系后台。
原标题:《P/NP问题50年:基础理论举步维艰,但AI正在不可能中寻找可能》
